- 사용자 SQL질의의 처리 가능 실행계획 탐색, 비용 산정, 최적의 실행 계획 수립하는 DBMS 핵심 엔진
나. 옵티마이저 주요 기능
기능
설명
실행 계획 탐색 (Search Space Enumeration)
- 주어진 SQL 질의를 처리할 수 있는 실행 계획들을 나열(P1, .... Pn)
비용 산정 (Cost Estimation)
- 각 실행 계획의 예상 비용을 계산하여 가장 비용이 적게 드는 실행 계획 Pi를 선택해서 SQL을 실행하고 결과를 사용자에게 제공
다. 옵티마이저 처리 절차
질의 처리 단계
주요 기능
설명
1). Query Rewrite
질의 변환기
- 옵티마이저가 더욱 효과적인 QEP를 찾기 위하여 더 효과적인 플랜이 있는지 그 가능성을 확인하는 과정
2). Query Optmization
비용 산정기
- 질의에 대한 엑세스 경로를 결정(규칙 기반 / 비용 기반 옵티마이저 사용)
3). QEP Generation
실행 계획 생성기
- 질의 실행 계획(Query Execution Plan) : 질의를 실행하는데 필요한 상세한 정보를 생성.
II. 규칙 기반 옵티마이저, RBO(Rule Based Optimzer)
항목
설명
개념
- 인덱스 구조나 비교연산자에 따른 순위여부를 기준으로 최적의 경로를 설정하는 규칙 기반 옵티마이저
특징
- 판단이 규칙적이고 분명하여 사용자가 정확히 예측 통계정보라는 현실요소를 무시하여 판단의 오차가 크게 날 수도 있음.
우선순위
Path 1: Single Row by ROWID Path 2: Single Row by Cluster Join Path 3: Single Row by hash Cluster Key with Unique or Primary Key Path 4: Single Row by Unique or Primary Key Path 5: Clustered Join Path 6: Hash Cluster Key Path 7: Indexed Cluster Key Path 8: Composite Index Path 9: Single-Column Indexes Path 10: Bounded Range Search on Indexed Columns Path 11: Unbounded Range Search on Indexed Columns Path 12: Sort_Merge Join Path 13: MAX or MIN of Indexed Column Path 14: ORDER BY on Indexed Column Path 15: Full Table Scan
예 시
Emp 테이블에 ‘A’ 인덱스가 “deptno”로 구성, ‘B’ 인덱스가 “deptno+empno”로 구성시 다음의 SQL은 Bounded Range Search(Between)이므로 ‘A” 인덱스를 사용. 즉 ’A’인덱스는 Rank 9이고 ‘B’인덱스는 Rank 10 조건이 됨 SELECT /*+ Rule */ from emp where deptno = 10 and empno between 7888 and 8888;
III. 비용 기반 옵티마이저, CBO(Cost Based Optimzer) 개념, 처리과정
가. 비용 기반 옵티마이저 개념
항목
설명
개념
- 처리 방법들에 대한 비용을 산정해 보고 그 중, 가장 적은 비용이 들어가는 처리방법을 선택하는 옵티마이저
특징
- 현실을 감안한 판단, 통계 정보의 관리를 통해 최적화 제어, 옵티마이저를 깊이 이해하고 있지 않더라도최소 성능을 보장하는 실행 계획을 미리 예측
원리
시스템 통계정보(CPU, 디스크 엑세스 타임을 이용하여 처리시간으로 환산한 방식)을 사용 SQL문장에 대한 여러가지 경우의 수 별로 처리시간에 비례한 비용을 산출해 내고 이들 비용에서 가장 작은 비용을 갖는 플랜을 결정
예 시
SELECT * FROM dept WHERE deptno= 10의 SQL 에서 dept테이블은 deptno에 대한 인덱스가 있 고 테이블은 전체 10블록으로 구성되어 있으며 풀 테이블 스캔일 경우 I/O 단위를 결정하는 파 라미터가 db_file_multiblock_read_count=8 이라면 RBO는 무조건 인덱스를 타는 플랜을 결정하지만 CBO는 deptno의 인덱스를 이용해 실행하면 3회의 I/O가 발생한다고 가정하고 풀 테이블 스 캔의 경우 2회(8블고+2블고)의 I/O가 발생한다면 인덱스가 있음에도 풀테이블 스캔을 선택함
나. 비용 기반 옵티마이저 처리 과정
- CBO는 옵티마이저의 통계 정보를 활용한 비용(Cost) 계산을 통해 최적 실행계획 도출
다. CBO 기반 SQL 최적화 수행 과정 구성요소
수행 과정
구성 요소
설명
1). SQL 파싱 과정
SQL Parser
- Parsing Tree 생성, SQL 문장 개별 구성요소 분석, - 문번적 오류(Syntax), 의미상 오류(Semantic) 확인
2). Optimization 과정
2-1). Query Transformer(쿼리 변환)
- Parsed SQL 표준(Canonical) 형태 변환 ex) 서브쿼리, 뷰 -> Join 형태로 변경
2-2). Estimator(비용산출)
- Dictionary 통계활용, 비용(Cost) 산출 - 선택도(Selectivity), 카디널리티(Cardinality) 계산
DBMS에서 동시에 작동하는 여러개의 트랜잭션이 작업을 성공적으로 종료하도록 실행순서를 제어하는 기법
다중 사용자 환경을 지원하는 데이터베이스 시스템에서 다수의 트랜잭션 작업이 성공적으로 실행될 수 있도록 지원하는 제어 기능
동시에 실행되는 다수의 트랜잭션 작업에서도 데이터베이스의 작업(입력, 수정, 삭제, 검색) 시 데이터의 무결성이 유지 되도록 제어하는 기법
2) 동시성 제어의 목적
일관성 측면 : 트랜잭션의 직렬 가능성을 확보하여 데이터의 일관성 보장, 데이터 무결성 보장
공용성 측면 : 시스템의 활용도, 공유 최대화, 사용자 응답시간 최소화
2. 동시성 제어 미처리 시의 문제점
구분
현상
설명
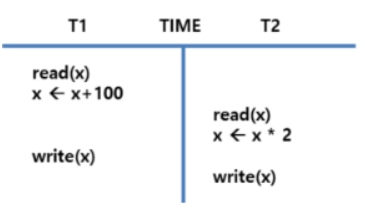
갱신 손실 (Lost Update)
- 트랜잭션들이 동일 데이터를 동시에 갱신할 경우 발생
현황파악오류 (Dirty Read)
-ㅠ트랜잭션의 중간 수행결과를 다른 트랜잭션이 참조함으로써 발생하는 오류
모순성 (Inconsistency)
- 두 트랜잭션이 동시에 실행할 때 DB가 일관성이 없는 상태로 남는 문제
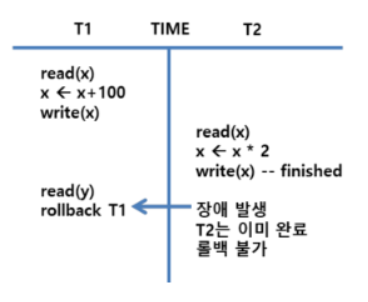
연쇄복귀 (Cascading Rollback)
- 복수의 트랜잭션이 데이터 공유시 특정 트랜잭션이 처리를 취소할 경우 다른 트랜잭션이 처리한 부분에 대해 취소 불가능
- 경신손실, 현황파악오류, 모순, 연쇄복귀 발생으로 병행제어 필요
3. 동시성 제어 기법의 종류
1) 동시성 제어 기법
낙관적, 비관적으로 분류하여 동시성 제어 수행
2) 동시성 제어 기법의 종류
기법
개념도
작동방식
Locking 기법
-트랜잭션이 사용하는 자원에 대하여 상호 배제 기능을 제공하는 기법 -공유 lock : 다른 트랜잭션도 읽기 실행 가능 -전용 lock : 다른 트랜잭션은 읽기, 기록 모두 불가
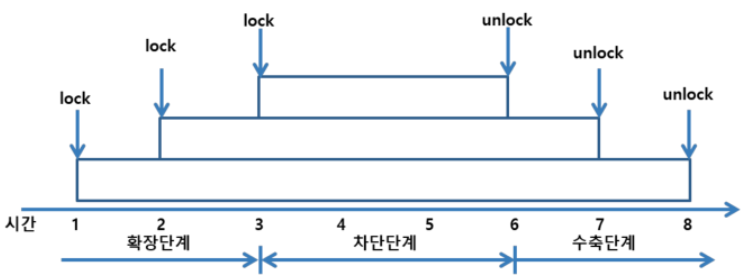
2PL (2 Phase Locking)
-확장단계 : 트랜잭션은 오직 lock만 수행 가능 -수축단계 : 트랜잭션은 오직 unlock만 수행 가능 -모든 트랜잭션들이 lock과 unlock연산을 확장 단계와 수축 단계로 구분하여 수행함
Timestamp Ordering
-시스템 시계 : 시스템 시간을 타임스탬프 값으로 부여 -논리적 계수기 : 트랜잭션 발생시마다 카운터를 하나씩 증가시켜 타임스탬프로 부여 -DB시스템에 들어오는 트랜잭션 순서대로 System Clock / Logical Counter 할당하고 순서를 부여하여 동시성 제어의 기준으로 사용
낙관적 검증기법
-트랜잭션 수행 동안 트랜잭션을 위해 유지되는 데이터 항목들의 지역 사본에 대해서만 갱신이 이루어짐 -트랜잭션 종료 시 동시성을 위한 트랜잭션 직렬화가 검증되면 일시에 DB에 반영함 -트랜잭션 수행 동안은 어떠한 검사도 하지 않고, 트랜잭션 종료 시 일괄적 검사 기법
다중버전 동시성 제어 (MVCC)
-트랜잭션이 한 데이터에 접근하려 할 때, 그 트랜잭션의 타임스탬프와 접근하려는 데이터의 여러 버전의 타임스탬프를 비교하여, 현재 실행하고 있는 스케줄의 직렬 가능성이 보장되는 버전을 선택하여 접근하도록 하는 기법 -트랜잭션의 타임스탬프와 접근 데이터의 여러 버전 타임스탬프 비교하여 직렬 가능성이 보장되는 버전 선택
4. 동시성제어의 문제점 및 해결방안
1) 동시성제어의 분류
Locking 해제 과정, 타임스탬프 부여에 따라 Deadlack, Rollback, 자원 낭비 등의 문제 발생
2) 동시성제어 문제점
기법
문제점
설명
Locking(2PL)
Deadlock 발생
- 락킹과 해제과정 중 서로 교착상태 조건 충족시 서로 대기하는 상태 발생
Timestamp
롤백
- 타임스탬프 비교에 따른 롤백
낙관적 검증
자원낭비
- 트랜잭션 마지막 단계에서 기록하는 낙관적 검증 기법은 자원낭비 문제 발생
MVCC
롤백
- 충돌문제는 대기가 아니라 복귀처리 함으로 연쇄 복귀초래 발생 가능성
문제점에 따라 선택적 기법 활용
3) 동시성제어 문제 발생 시 해결방안
타임스탬프 적용 시 Wait-die, Wond-wait 적용
비고
Wait-die
Wound-wait
정의
오래된 트랜잭션 기다리고, 새로운 트랜잭션이 Rollback 되고 다시 계획
오래된 트랜잭션이 새로운 트랜잭션을 rollback 시키고 이를 다시 계획
트랜잭션 양
lock을 요청하는 단계 중에 abort되어 재시작되므로, abort되는 트랜잭션의 처리된 양이 적음
처리도중 높은 우선 순위 트랜잭션에 의해 abort되므로, 그 동안 처리된 일이 모두 무시되어 불필요한 작업 수행
공통점
- 두 방법 모두 우선 순위가 높은 트랜잭션이 낮은 우선순위의 트랜잭션을 abort 시킴 - 중지된 트랜잭션은 기존 타임스탬프를 가지고 재시작 - 결국 시스템에서 가장 높은 우선 순위를 갖게 되어 완료됨 - 구현이나 관리가 waits-for graph보다 쉬움