XIV. 빅데이터 및 NoSQL에 대한 이해
- 목표 : 빅데이터 개념과 관련 기술, NoSQL의 개념과 특징
- 핵심 키워드 : 빅데이터, 3V, 비정형데이터, 분산파일시스템(DFS), NoSQL, CAP이론
01 빅데이터의 개요
가. 빅데이터 정의 및 특징
1) 빅데이터 정의
- 기존 DB 관리도구의 데이터 수집, 저장, 분석하는 역량을 넘어서는 데이터
- 다양한 종류의 대규모 데이터로부터 저비용으로 추출, 빠른 수집, 발굴, 분선을 지원하는 차세대 기술 및 아키텍처
2) 빅데이터 특징(3V)
| 3대 요소 | 설명 |
| 크기(Volume) | - 수십 테라바이트(Terabyte)/페티바이트(Petebyte) 이상의 데이터 |
| 속도(Velocity) | - 고속 생성, 실시간 처리(수집, 처리, 저장, 분석) |
| 다양성(Valiety) | - 다양한 종류 데이터(정형, 반정형, 비정형) |
- 빅데이터 6V : Volume, Variety, Velocity + Veracity(진실성), Visualization(시각화), Value(가치)
3) 정형 데이터 VS 비정형 데이터
| 데이터 형태 | 설명 |
| 정형(Structured) | - 고정된 필드에 저장되는 데이터 |
| 반정형(Semi-Structured) | - XML, HTML 처럼 메타 데이터나 스키마 포함 데이터(CVS, XLS, RDF) |
| 비정형(Unstructed) | - 문서, 그림, 동영상, 오디오, 비디오 |
나) 빅데이터의 Life Cycle별 세부기술
| 구분 | 설명 | 세부기술 |
| 수집 | - 데이터 수집 기술 | - 크롤링(웹로봇), ETL, CEP |
| 저장/처리 | - 분산 저장/처리 | - DFS, NoSQL, MapReduce |
| 분석 | - 유의미한 정보 추출 | - NLP, ML, 데이터 마이닝 |
| 표현 | - 분석 결과의 효과적 표현 | - R, 그래프, 도면, 시각화 |
* CEP(Complex Event Processing, 실시간 복합 이벤트 처리)
- 실시간 데이터의 가시화를 통해 이벤트 간 연관성, 패턴을 이해하고 유의미한 정보를 통해 다양한 비즈니스 가치를 창출하는 과정
02. 빅데이터 관련 기술
가) 수집기술
- ETL, 웹 크롤링, RSS Feeding, Open API, CEP
- 웹 크롤링 : 웹 문서, 데이터 자동 수집(SNS, 블로그, 뉴스), HTML 코드 분석, 특정 태그 데이터 수집
| 기술 | 설명 | 솔루션 |
| DBMS 이용 | SQL 기능 이용 | Oracle, MariaDB, Tibero |
| 센서 이용 | 일정 조건 만족 시 데이터 수집 | CQL, Kafka |
| FTP 수집 | 파일 이동 포트 이용 수집 | |
| HTTP 수집 | HTML 태그 이용 수집 | 스크래퍼 |
나) 빅데이터 저장/처리 기술
| 기술 | 설명 | 솔루션 |
| 분산파일시스템(DFS) | - 대용량, 비정형 데이터의 분산 저장/처리 아키텍처 - 가격 저렴, Scale-Out, 고가용성, Batch 처리 |
GFS(Google File System), HDFS(Hadoop DFS) |
| NoSQL | - BASE특성의 저장/검색 시스템 - 유연한 스키마, 비 관계형 모델, 확장성 |
HBase, Cassandra, MongoDB, CouchBase, Redis, Neo4J |
| MapReduce | - 클러스터 환경에서의 병렬 분산 처리 프레임워크 - HDFS 연동, 다양한 옵션 |
HDFS |
- 최근 클라우드 환경에서 가상화 기술 이용한 클라우드 기반 분산 파일 시스템 도입 중
다) 표현기술
- 이해하기 쉽도록 분류, 통계, 그래프 이용하는 기법

라) 빅데이터 분석
- 빅 데이터로부터 의미 있는 패턴을 발견하는 것
마) 주요 빅데이터 분석 방법
| 개념 | 설명 |
| 로지스텍 회귀분석 (Logistic Regression) |
- 독립변수의 선형결합 이용, 사건의 발생확률 예측 기법 |
| 의사결정트리 분석(Decision Tree) | - 의사결정 규칙을 도표화, 소집단으로 분류, 예측하는 계량적 분석방법 |
| 신경망 분석(Neural Network) | - 인간 두뇌 모방, 네트워크 기반으로 병렬, 분산, 확률적 계산 분석방법 |
| 텍스트 마이닝 (Text Mining) | - Test 데이터를 NLP, 문서처리 기술 적용하여 추출/가공하는 기술 - 핵심기술 : 요약, 분류, 군집, 특성 추출 |
| SNA (Social Network Analysis) | - 객체 간의 관계, 네트워크의 특성/구조 분석, 시각화화는 분석방법론 |
| Opinion Mining | - 비정형 리뷰에서 정보 분석, 지능적 유추 기술 - 핫 이슈 추출, 여론 분석, 마케팅 정책에 활용 |
| 자연어처리(NLP) | - 사람의 언어를 이해, 생성, 분석하는 AI기술 - 절차 : 전처리 → 형태소 분석 → 구문분석 → 의미분석 → 담화분석 |
바) 데이터 과학자
- 데이터 수집, 정리, 조사, 분석, 가시화 전문가. 데이터를 이용해 기업/조직에 필요한 정보 제공
03. NoSQL
가) NoSQL 정의 및 특징
- 비정형, 초고용량 데이터 처리 위해 쓰기속도 증가, 복제/분산 저장, 수평적 확장이 가능한 비관계형 분산 데이터 저장소
- 특징
| 특징 | 설명 |
| 대용량 데이터 처리 | - 페타바이트 수준 처리 가능, 느슨한 데이터 구조 |
| 유연한 스키마 | - 유연한 저장, Key-value, Graph, Document 구조 |
| 저렴한 클러스터 구성 | - 상용 HW 활용, 수평적 확장, 복제 및 분산 저장 |
| 단순한 CLI | - 쿼리 언어 없음, API Call, Http 이용 단순한 인터페이스 |
| 고가용성 | - 클러스터 환경에 자동 분할, 적재 |
| 적정한 무결성 | - BASE 기반, 무결성을 응용에서 일부 처리 |
| Schema-Less | - Key 이용 저장, 접근 기능 사용, 칼럼, 값, 문서, 그래프 방식 |
| 탄력성 | - 성능 확장 용이, 입출력 부하 분산 용이 |
| 질의가능(Query) | - 대규모 시스템에서 검색/처리 가능한 질의언어, API 제공 |
| 캐싱(Caching) | - 파티셔닝 통한 점진적 노드 추가 가능 |
| 높은 확장성 | - 메모리 기반 처리, 논블락킹 Write/단순한 알고리즘 사용 |
| 원자성 | - 각각의 쓰기는 원자성 보유 |
| 일관성 | - 결과적 일관성 보유 |
| 지속성 | - 데이터는 디스크에 유지 |
| 배포의 유연함 | - 노드 추가/삭제 자동 로드, 이기종간 동작 가능 |
| 모델링의 유연함 | - Key-value쌍, 계층적 데이터, 그래프 등 다양한 모델링 가능 |
| 퀴리의 유연함 | - 다중 GET, 범위 기반 쿼리 가능 |
나) NoSQL의 BASE 속성
| 구분 | 설명 |
| Basically Available | - 가용성 중시, Optimistic Locking/규 사용 - 다수 스토리지에 복제를 통해 가용성 보장 |
| Soft-State | - 외부의 전송 정보를 통해 노드 상태 결정 - 데이터가 노드에 도달한 시점에 갱신 |
| Eventually Consistent | - 일시적 비일관적 상태 → 최종적으로는 일관성 성립 |
BASE 속성과 ACID 속성 비교
| 속성 | BASE | ACID |
| 분야 | NoSQL | RDBMS |
| 범위 | 시스템 전체 특성 | 트랜잭션에 한정 |
| 일관성 측면 | 약한 일관성 | 강한 일관성 |
| 중점사항 | ‘Availability’에 집중 | ‘Commit’에 집중 |
| 시스템 측면 | ‘성능’에 초점 | ‘엄격한 데이터 관리’에 초점 |
| 효율성 | ‘쿼리 디자인’이 중요 | ‘테이블 디자인’이 중요 |
다) NoSQL의 저장방식
- NoSQL 종류
| 종류 | 설명 |
| Key-Value 기반 | - 단순/빠른 Get, Put, Delete 기능 제공 - Dynamo, Redis, MemcacheDB |
| Column Family 기반 | - 칼럼 패밀리에 행으로 데이터 저장 - Cassandra, HBase, SimplDB |
| Document 기반 | - 문서를 Key-Value의 Value 부분에 저장 - MongoDB, CouchDB |
| Graph 기반 | - 엔트리 속성을 노드로, 관계를 엣지로 표현 - Neo4J, 플록DB |
라) NoSQL 데이터 모델의 특징 비교
| 방식 | 관계형DB 데이터 모델링 | NoSQL 데이터 모델링 |
| 개념도 |  |
 |
| 핵심 | - ACID 기반 데이터 모델링 | - BASE기반 데이터 모델링 |
| 방식 | - 최소 중복 통한 데이터 일관성 확보 | - 데이터 중복통한 빠른 조회 확보 |
| 단계 | - 데이터 모델링(설계)후 개발 | - 화면, 개발 로직 고려한 데이터셋 설계 |
| 독립성 | - 프로그램 독립적 설계(데이터 독립성 중요) | - 프로그램 종속적 설계(데이터 독립서 회피) |
| 특징 | - 논리적 연결점 보유한 모델링 기법 | - 파일구조 설계에 근접 |
마) NoSQL 데이터 모델의 특징
1) CAP 이론의 정의
- 대용량 분산 DB는 일관성(Consistency), 가용성(Availability), 단절내성(Partition Tolerance)을 모두 만족시키는 것은
불가능, 두 가지만 전략적으로 선택해야 한다는 이론
2) CAP 이론의 구성과 관리 전략
| 특성 | 설명 |
| 구성도 | 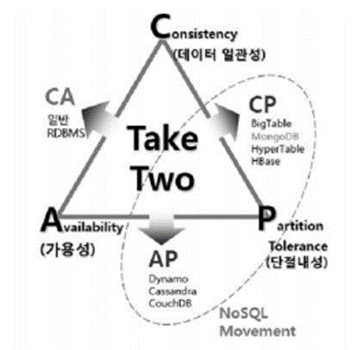 |
| Consistency | - 각 사용자는 항상 동일한 데이터 조회 |
| Availability | - 소수 노드 장애 발생에도 다른 노드에 영향 없음 |
| Partition Tolerance | - 일부 메시지 손실에도 시스템은 정상 동작 |
| C + A | - 메시지 손실 방지하는 강한 신뢰성, 일반 RDBMS |
| C + P | - 모든 노드가 함께 퍼포먼스 내는 성능형, Big Table, Hyper Table, HBase |
| A + P | - 비동기화된 스토어 작업에 필수적 - Dynamo, Apache Cassandra, CouchDB, Oracle Coherence |
- NoSQL 시스템들은 A+P, C+P의 특성을 가지는 분산시스템들로 구성
'TOPCIT > TOPCIT교재' 카테고리의 다른 글
| XIII. 데이터베이스 분석 이해 - 이상희 (0) | 2022.07.27 |
|---|---|
| XII. 데이터베이스 복구 - 이강욱 (0) | 2022.07.27 |
| VII. 데이터베이스 품질과 표준화 - 안혜진 (0) | 2022.07.26 |
| III. 데이터베이스 설계 및 구축절차 - 문경숙 (0) | 2022.07.26 |
| XI. 동시성제어-윤정우 (0) | 2022.07.25 |