01. 병렬 처리 시스템(Parallel Processing System)
가) 병렬 처리 시스템의 개념
- 두개의 연산을 처리해야 하는 문제가 있는데 두개의 연산이 서로 의존성이 없다면 한 개의 연산이 완료될 때까지 나머지 연산을 기다리지 않고 동시에 처리하는 행위
- 프로그램 명령어를 여러 프로세서에 분산시켜 동시에 수행함으로써 빠른 시간 내에 원하는 답을 구하는 작업
나) 병렬 처리 시스템의 플린에 의한 분류

| 유형 | 구조 | 설명 |
| SISD 단일명령-단일자료 (Single Instruction Stream Single Data Stream) |
 |
- 1 회 1 개씩 명령어 데이터 처리, 폰노이만 구조 - 성능향상 위한 처리가능 (파이프라인 등) |
| SIMD 단일명령-다중자료 (Single Instruction Stream Multiple Data Stream) |
 |
- 여러 개의 프로세싱 유닛(PU)로 구성되고, 하나의 제어 유닛(CU)에 의해 통제됨 - 배열 프로세서, 다수 데이터를 하나의 명령어로 실행 - 분산 기억장치 구성가능 |
| MISD 복수명령-단일자료 (Multiple Instruction Stream Multiple Data Stream) |
 |
- N개의 프로세서들이 서로 다른 명령어 실행 - 1개 데이터를 다수의 명령어로 처리 - 실제 설계 구현 사례 없음 |
| MIMD 복수명령-복수자료 (Multiple Instruction Stream Multiple Data Stream) |
 |
- N개의 프로세서들이 서로 다른 명령어들과 데이터들 처리 - 프로세서들 간 상호작용 정도에 따라 2가지로 분류(tightly-coupled system, loosely-coupled system) - 다수의 프로세서가 서로 다른 다수의 데이터 스트림을 처리 - 대부분의 병렬 시스템 |
다) 메모리 구조에 의한 병렬 처리 시스템 분류
| 유형 | 구조 | 설명 |
| SMP 대칭형 다중 프로세서 (Symmetric Mutiprocessor) |
 |
- 단일 처리기 시스템에서 나타나는 성능의 한게를 극복하기 위해 두 개 이상의 프로세서를 공유버스로 상호 연결하여 하나의 메모리를 망에 연결시켜 놓은 시스템 - MPP 시스템에 비해 병렬 프로그래밍이 쉽고, 프로세서간 작업 분산이 쉬움 - MPP에 비해 확장성이 낮음 |
| MPP 거대 병렬 프로세서 (Massice Parallel Processor) |
 |
- 각 프로세서는 개별 메모리를 이용하여 일을 수행하는 비공유 아키텍처 - 비공유 아키텍처이기 때문에 단일병합(병목) 지점이 없고, 대규모 시스템 확장이 가능
- 프로세서 간에는 메시지 패싱과 같은 기법을 이용하여 통신
- 확장성이 뛰어나며 대용량의 DB를 지원
- 개발 비용이 적게 소요
|
| NUMA 불균일 기억장치 액세스 (Non Uniform Memory Access) |
 |
- 메모리에 접근하는 시간이 CPU와 메모리의 상대적인 위치에 따라 달라지는 컴퓨터 메모리 설계 방법 - NUMA 아키텍처는 이론적으로 SMP 아키텍처에서 확장 된 개념
- 개별 프로세서에 별도의 메모리를 제공, 메모리의 동일 주소 접근 시 발생하는 충돌 해결
- 중간 단계의 공유메모리를 추가하여 모든 데이터 엑서스가 주 버스 상에서 움직이지 않음
|
라) 병렬 프로세서 기술의 유형
| 유형 | 구조 | 설명 |
| 명령어 파이프라이닝 (Pipelining) |
 |
- 명령어를 읽어 순차적으로 실행하는 프로세서에 적용되는 기술 - 한 번에 하나의 명령어만 실행하는 것이 아니라 하나의 명령어가 실행되는 도중에 다른 명령어 실행을 시작하는 식으로 동시에 여러 개의 명령어를 실행하는 기법 |
| 슈퍼스칼라 프로세스 (Super Scalar) |
 |
- CPU 내에 파이프라인을 여러 개 두어 명령어를 동시에 실행하는 기술 - 파이프라인으로 구현된 여러개의 유닛이 명령어들의 병렬 처리를 지원하는 것 |
| 파이프라인 해저드 |  |
- CPU 성능 향상을 위한 파이프라인 프로세서에서 수행중인 명령어의 중첩처리를 방해하는 구조적, 데이터, 제어 측면의 위험요인 - 파이프라인 프로세싱에서 의존성으로 발생할 수 있는 문제로, 프로세서에서 수행중인 명령어의 중첩처리를 방해하는 위험 요인 - 구조적 해저드, 데이터 해저드, 제어 해저드 분류 |
마) 병렬 프로그래밍 기술
| 유형 | 구조 | 설명 |
| 컴파일러 기술 OpenMP |
 |
- 컴파일러 디렉티브(Directive) 기반의 병렬 프로그래밍 API - 최초 프로그램은 마스터 스레드로 동작하고 디렉티브를 만나면 스레드를 생성하여 스레드별로 독립적으로 수행 |
| 메시지 패싱 병렬 프로그래밍 모델 Message Passing Interface |
 |
- 노드 간 네트워크를 통해 메시지를 공유 - 메시지 패싱 병렬 프로그래밍을 위해 표준화된 데이터 통신 라이브러리 - 프로세서 대 프로세스, 일대일 또는 일대다로 작업 할당 |
| 부하 균등화(Load Balancing) 기술 AMP, SMPm BMP |
바) 그래픽 처리 프로세싱 기술
| 유형 | 구조 | 설명 |
| GPU (Graphics Processing Unit) |
 |
- 병렬처리용으로 설계된 수천 개의 소형이고 효율적인 코어로 구성 - 그래픽 처리장치로써 이미지와 영상을 처리하는 역할을 담당하는 그래픽카드의 핵심 반도체 - Floationg Point 연산을 하는 작은 ALU 코어를 수천개 반복 구성시켜 빠른 그래픽처리 수행 |
| GPGPU (General-Purpose GPU) |
 |
- GPU를 그래픽스 전용 처리뿐만 아니라, 범용적인 데이터 병렬처리가 가능한 그래픽 처리 유닛 - 기존의 CPU와 GPU를 결합, 기본적인 컴퓨팅 환경은 CPU가 담당하고 대량 데이터에 대한 신속한 연산이 필요한 영역은 GPU에게 맡기는 방식인 가속 컴퓨팅(GPU-accelerated computing) 확대 |
사) GPU 기반 병렬 프로그래밍 기술
| 유형 | 구조 | 설명 |
| CUDA (Compute Unified Device Architecture) |
 |
- GPU를 이용한 범용적인 프로그램을 개발할 수 있도록 ‘프로그램 모델’, ‘프로그램 언어’, ‘컴파일’, ‘라이브러리’,‘디버거’, ‘프로파일러’ 를 제공하는 통합환경 - 높은 연산 처리능력 - CPU 부하 감소 - 작은 메모리에서 병렬 수행 |
| OpenCL (Open Computing Language) |
 |
- 애플, AMD, Intel, IBM, NVDIA에서 개발한 개방형 범용 병렬 컴퓨팅 프레임워크 - 데이터와 태스크 기반의 병렬 프로그래밍 모델 - 오픈스펙 특징(GPU, CPU, DSP 사용 가능) |
| C++ AMP (C++ Accelerated Massive Paralleism) |
 |
- 마이크로소프트사가 개발한 CPU와 GPU를 사용한 이기종 컴퓨팅을 위한 개방형 프로그래밍 언어 - GPU를 이용한 C++ 코드의 실행 속도 향상 목적 |
| Open ACC |  |
- 크레이, CAPS, 엔비디아, PGI가 개발한 병렬 컴퓨팅을 위한 프로그래밍 표준 - 이기종 CPU/GPU 시스템의 병렬 프로그래밍을 단순하게 만들기 위해 설계된 것 - CPU와 GPU 아키텍처를 둘 다 대상으로 하여 이들 위에 연산 코드를 실행 |
02. 스토리지 기술
가) 저장장치의 개념
- 컴퓨터에서 데이터(자료)를 일시적 또는 영구히 보존하는 장치
- 자료를 파손이나 유실되지 않게 관리하는 장치
나) 저장장치와 서버의 연결
| 유형 | 구조 | 설명 |
| DAS (Direct Attached Stroage) |
 |
- DAS 구성에서는 HDD나 SDD와 같은 1개 이상의 데이터 스토리지 구성요소가 컴퓨터 안에 설치되거나 주로 SAS 링크를 통해 컴퓨터에 직접 연결 |
| NAS (Network Attached Storage) |
- LAN 환경에서 서버와 스토리지에 접속하는 방식 - SAN 스토리지 단점을 보완하기 위해 NAS 스토리지는 보편적인 TCP/IP 기반 LAN 채널 속도와 파일 시스템 공유가 가능하고, SAN 보다 상대적 낮은 유지보수 비용 발생 |
|
| SAN (Storage Area Network) |
- 서버와 공유 스토리지 장치 또는 스토리지 어레이 간에 Fiber Channel 또는 iSCSI로 연결된 네트워크 시스템 - SAN 환경에서 스토리지에 접속하는 방식(서버에 Fibre Channel HBA 필요) |
다) IP-SAN
- 기가비트 이더넷의 인터넷 프로토콜(IP)을 사용하는 SNA
- IP를 이용하여 네트워크 관리의 일원화 및 SAN의 거리제약 탈피 가능
| 유형 | 구조 | 설명 |
| FCIP (Fiber Channel Over IP) |
 |
- 원격지의 SAN 연결 시 사용, 원격지의 프레임 전송할 경우 TCP/IP로 캡슐화하여 상호 연결 - SAN에 손상이 발생할 경우 패브릭에 포함되어 있는 다른지역 SAN에 영향발생 |
| IFCP (Internet Fiber Channel Protocol) |
 |
- IFCP 게이트웨이(Gateway)를 통해 지역 SAN 사이의 고유의 TCP/IP로 연결 제공 - 한 지역 손상 시 다른 지역 영향 없음 - 게이트웨이를 이용한 프로토콜 변환방식, 인프라 변경 없이 구축 가능 -> 높은 상호 접속성 제공 |
| ISCS (Internet SCSI) |
 |
- SCSI 명령을 IP 패킷으로 캡슐화하여 I/O 블록 데이터를 TCP/IP를 통해 전달 - IPSec등의 기술을 통한 높은 신뢰성 제공 - 기존 네트워크 환경 사용이 가능하여 네트워크 스토리지 구축 비용 절감 효과 |
라) 스토리지 용량 관리 기술
| 유형 | 구조 | 설명 |
| 씬 프로비저닝 (Thin Provisioning) |
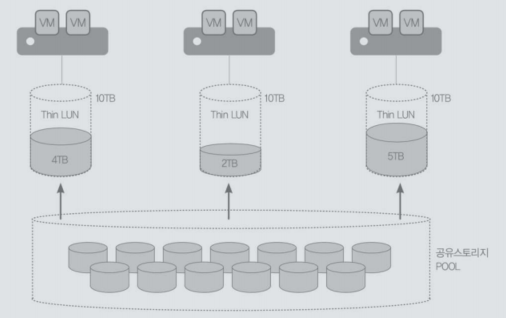 |
- 실제 데이터의 사용하는 공간을 Thin LUN으로 매핑하여 데이터를 할당하는 스토리지 가상화 기술 - 클라우드 컴퓨팅에서 사용자가 요구하는 디스크 공간 유연한 확장 가능 |
| 데이터 디 듀플리케이션 (Data De-Duplication) |
 |
- 데이터 저장 시 중복 데이터를 제거하여 디스크 공간 효율화 제공 - 인라인 방식 저장 : 데이터가 들어가는 순간 중복 데이터 바로 제거 - 오프라인 방식 저장 : 저장을 완료한 후 저장된 중복 데이터 제거 |
마) 저장장치 디스크 스케줄링
- 주 기억장치에 부재중인 데이터를 디스크로부터 불러오는데 소요되는 시간을 최소화하기 위한 스케줄링 기법
- 디스크 성능 측정 지표 : 접근시간(Access Time), 탐색시간(Seek Time), 회전대기(Rotational delay or rotational latency), 데이터 전송시간(Data Transfer Time)

| 유형 | 설명 |
| FCFS (First Come First Service) |
- 요청 큐에 들어온 순서대로 처리, 탐색패턴 최적화 미실시(공정/비선점) 입출력 증가 시 평균 응답시간 증가 - 알고리즘 단순 구현 용이, 공정한 스케쥴링 기법 - 비효율적인 탐색 순서 |
| SSTF (Shortest Seek Time First) |
- 현재 헤드 위치에 가장 가까운 트랙의 요청 처리 - Throughput 극대화, Seek Time 최소화 - 안쪽, 바깥 쪽 트랙 기아상태 발생 가능성, 응답시간 편차가 큼 |
| SCAN 디스크 스케줄링 | - 가장 안/바깥쪽 실린더 도착 시 방향 전환 - 기아가 발생하는 SSTF 의 차별대우 개선, 응답시간 편차가 작음 - 양 쪽 끝 트랙은 가운데 위치한 트랙보다 대기시간이 길어짐 |
| LOCK 디스크 스케줄링 | - 헤드가 진행하는 도중 진행 방향의 앞쪽으로 더 이상의 요구가 없으면 양 끝의 실린더까지 진행하지 않고 그 자리에서 방향을 바꿈 |
| C-SCAN 디스크 스케줄링 (Circular SCAN) |
- 항상 바깥쪽에서 안쪽으로 SCAN 을 수행 끝에 도달하면 다시 처음으로 이동 - 입출력 요청에 균등한 대기시간 제공 - 안쪽이나 바깥쪽을 처리할 요청이 없어도 끝까지 진행 |
| C-LOCK 디스크 스케줄링 (Circular LOCK) |
- C-SCAN과 같이 처리하되 처리할 블록이 없으면 끝까지 가지 않고 돌아옴 - 불필요한 헤드 이동시간 제거 - 진행여부 결정 위한 오버헤드 |
03. 고가용성 저장장치
가) RAID(Redundant Array of Independent Disk) 기술
- 여러 드라이브의 집합을 하나의 저장장치처럼 다룰 수 있게 하고, 장애가 발생했을 때 데이터를 잃어버리지 않게 하며 디스크 각각이 독립적으로 동작할 수 있도록 하는 저장장치 기술
- 다수의 디스크에 데이터를 중복으로 저장하여 가용성과 성능을 향상시키는 저장장치 기술
- 가격이 저렴하고 크기가 작은 여러 개의 독립된 하드 디스크들을 묶어 하나의 기억장치로 사용할 수 있는 방식
- 데이터 손실 시 안전한 복구 기능과 디스크 확정성 확보
| 유형 | 구조 | 설명 |
| RAID 0 (블록 레벨 스트라이핑) |
 |
- 블록 저장 시 각 블록을 다른 디스크에 나누어 저장하는 방식, 최소 2개 – 가용용량: D – 고장허용: 0 ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 2개 – 쓰기 속도 우수 – 하나의 디스크 고장 시 전체 영향 |
| RAID 1 (디스크 미러링) |
 |
블록이 디스크에 각각 저장되고 모든 데이터는 중복 방식, 최소 2개 – 가용용량: D / 2 – 고장허용: D / 2 ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 2개 – 안전성 우수, 읽기 성능 우수 – 디스크 추가 시 2배 비용, 전체 용량 절반 효율 |
| RAID 2 (비트레벨 스트라이핑, 전용 해밍코드 디스크) |
 |
– 전용 해밍코드 에러 수정 방식 사용 비트 레벨 스트라이핑 구성 방식, 자체 해밍코드 에러 수정이 가능해지며 현재는 미사용 – 가용용량: D – R – 고장허용: R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 3개 – 한 개의 디스크가 고장 허용, 쓰기/읽기 성능 우수 – 현재는 사용하지 않으며, 임의 쓰기 성능 미흡 |
| RAID 3 (바이트 레벨 스트라이핑, 전용 패리티 비트 디스크) |
 |
– 바이트 단위 모든 디스크에 균등 저장되는 바이트 레벨 스트라이핑 구성방식 패리티정보 별도 저장 – 가용용량: D – R – 고장허용: R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 3개 – 한 개의 디스크가 고장 허용, 쓰기/읽기 성능 우수 – 잘 사용하지 않으며, 임의 쓰기 성능 미흡 |
| RAID 4 (블록 레벨 스트라이핑, 전용 패리티 디스크) |
 |
– 파일은 블록으로 쪼개 여러 디스크에 저장되지만 균등하지 않고, 패리티 정보 별도 디스크에 저장 – 가용용량: D – R – 고장허용: R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 3개 – 한 개의 디스크 고장 허용, 쓰기 성능 우수 – 쓰기 성능이 미흡 |
| RAID 5 (블록 레벨 스트라이핑, 패리티 분산) |
 |
– 블록은 모든 디스크에 나누어 저장되지만 균등하지 않고, 패리티 정보도 모든 디스크 나누어 저장 – 가용용량: D – R – 고장허용: R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 3개 – 1 개의 디스크 고장 허용, 읽기 속도 우수 – 디스크 재구성이 매우 느리고 패리티 정보 갱신으로 인해 쓰기 성능 저하 |
| RAID 6 (블록 레벨 스트라이핑, 패리티 이중 분산) |
 |
– 블록은 모든 디스크에 나누어 저장되지만 균등하지 않고, 패리티 정보도 이중으로 모든 디스크 나누어 저장 – 가용용량: D – 2R – 고장허용: 2R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 4개 – 2 개의 디스크 고장 허용, 읽기 성능 우수 – 패리티 정보 갱신으로 인해 쓰기 성능이 저하되며, 디스크 재구성 시 성능이 매우 저하 |
| RAID 1+0 |  |
– 각각 미러링(RAID-1)한 볼륨을 스트라이핑(RAID-0)으로 구성으로 RAID-0의 속도와 RAID-1의 안정성 갖춘 디스크 구성 방식 – 가용용량: R / 2 – 고장허용: R / 2 ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 4개 – 2 개의 디스크 고장 허용, 읽기/쓰기 성능 우수 – 디스크 구성 비용이 일반 디스크의 4배로 고비용 |
| RAID 0+1 |  |
– 각각 스트라이핑(RAID-0) 볼륨을 미러링(RAID-1)으로 구성으로 RAID-1의 안정성과 RAID-0의 속도를 갖춘 디스크 구성 방식 – 가용용량: R / 2 – 고장허용: R / 2 ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 4개 – 2 개의 디스크 고장 허용, 읽기/쓰기 성능 우수 – 일반 디스크 4배 비용, Disk Fault 시 복구 위해 RAID-1+0보다 긴 시간 필요 |
| RAID 0+5 |  |
– 각각 스트라이핑(RAID-0) 볼륨을 미러링(RAID-1)으로 구성으로 RAID-1의 안정성과 RAID-0의 속도를 갖춘 디스크 구성 방식 – 가용용량: D – R – 고장허용: R ※ (D: Disk개수, R: RAID 개수) ※ 최소 구성 Disk 6개 – 2 개의 디스크 고장 허용, 읽기/쓰기 성능 우수 – 일반 디스크 대비 고비용, 속도와 안정성 높음 |
나) 백업 스토리지: LTO, VTL
- LTO(Linear Tape-Open) : 고속 데이터 처리 및 대용량을 지원하는 공개 테이프 드라이브 표준 기술
- VTL(Virtual Tape Devices) : 디스크 스토리지를 애뮬레이션하여 가상의 테이프 장비로 만들어 주는 백업 솔루션

04. 그래픽 압축 기술
가) 영상압축 유형
- 데이터의 전송 및 저장 효율을 높이기 위해 원본 데이터에서 불필요한 데이터를 삭제하거나 데이터 중복을 제거하여 원래의 크기보다 적은 사이즈의 데이터로 변환하는 기술
- 데이터 저장공간과 전송 대역폭의 효과적인 이용을 위해 데이터 크기를 줄이는 기법
- 파일이나 통신 메시지와 같은 데이터 집합의 크기를 절약하거나 전송 시간을 단축하기 위해 데이터를 좀 더 적은 수의 비트를 사용하도록 부호화하는 기술
- 데이터의 시간적 중복성(소리) 및 공간적 중복성(영상)을 이용
| 분류 | 유형 | 설명 |
| 무손실 | LZW(Lempel–Ziv–Welch)코딩 |
|
| Run-Length 코딩 |
|
|
| 허프만 코딩 |
|
|
| 손실 | 변환 코딩 |
|
| 예측 코딩 |
|
|
| 양자화 |
|
|
| 보간 기법 |
|
나) 멀티미디어 데이터
- 멀티미디어 데이터에는 텍스트, 이미지, 비디오, 오디오 데이터가 있으며, 텍스트는 평문(Plain Text), 비선형 하이퍼 텍스트(Hypertext) 형태를 가지며, 기본 언어는 심볼들을 표현하기 위한 유니코드(Unicode)이며, 무손실 압축방식
- 이미지는 정지영상으로 불리며 사진, 팩스 페이지, 동영상의 프레임 하나를 의미하며 변환과정>양자화 과정>보호화 과정을 거쳐서 2진 데이터로 전송

- 동영상 압축 표준

- ACV(Advanced Vedio Coding)와 HEVC(High Efficiency Vedio Conding) : AVC 코덱은 국제 표준화 기구인 ITU-T와 ISO에서 공동으로 제안한 비디오 압축 기술
'TOPCIT > TOPCIT교재' 카테고리의 다른 글
| 11. 데이터 링크계층 - 김도현 (0) | 2022.08.01 |
|---|---|
| 9. 클라우드 컴퓨팅 기술 - 문경숙 (0) | 2022.08.01 |
| 3. 운영체제 - 이강욱 (0) | 2022.08.01 |
| 2. 네트워크 개념 - 이상희 (0) | 2022.08.01 |
| 1. 시스템 개념 - 황선환 (0) | 2022.08.01 |